Intro to Neo4j
SQL databases are really fast when you need all the information stored together in a record row, but they are a bad fit when you need to search for relationship patterns that are not already stored together in your database. A significant performance penalty is incurred for every additional table that needs to be joined for a query. That is why SQL databases are notoriously bad at deducting relationships from datasets. Graph databases however are really good at this task.
Neo4j, a very popular open source graph database stores its data in a property graph, as described in Graph Databases for Beginners on the project’s website:
- Property graphs contain nodes (data entities) and relationships (data connections).
- Nodes can contain properties (tech lingo: key-value pairs).
- Nodes can be labeled with one or more labels.
- Relationships have both names and directions.
- Relationships always have a start node and an end node.
- Like nodes, relationships can also contain properties.
In combination with a graph query language called Cypher that is optimised for between-record pattern recognition, this storage pattern makes it easy to write queries that search for new patterns in a database and for objects that have a specified relationship with another object.
This makes graph databases excel at a number of tasks:
- Explore large non-uniform datasets: Neo4j got a lot of attention after it was used by investigative journalists to identify the organisations and individuals involved in offshore tax evasion in the Panama papers leak.
- Recommend content: Media companies like the Finacial Times are using Neo4j to display related content on their website, this helps them to increase engagement with higher clickthrough rates.
- Personalisation: Adidas uses the Neo4j graph database to create it’s internal metadata service, offering access and searchability to their data and making sense of complex interdependencies and relationships.
Why we built the module
We wanted to create a basic integration that makes it possible for non-developers to work with Neo4j. Combined with Drupal’s content modelling capabilities we believe it could be a powerful tool for people to explore graph databases using a GUI. There is also a case to be made for the use of graph databases in the Drupal ecosystem: sites that already use Drupal could benefit from its capabilities.
Drupal already had a module for Neo4j, that was originally built by Peter Arato, a former colleague. The module, developed a few years ago, however used the HTTP-only connector, and not the superior bolt connector. That is why we decided to reimplement the module, under a separate namespace.
With the bolt connector the new modules we created for Drupal 7 and 8 have a better performance. For both Drupal versions, the base module is an API module that provides settings for the connection and that supplies other modules with the connection object. This way developers can use the API module to build their own integrations (e.g. for applications that are contributed to the open source community or for integrations specific to an organisation).
Compatibility with Drupal 7 & Drupal 8
The module has support for both Drupal 7 and Drupal 8, however the versions have slightly different feature sets. Out of the box both versions have a page logging functionality that can help you discover browsing patterns of your visitors. The main difference is currently the rules support, as at this point we found it to be too much work to create a rules integration for Drupal 8. In the long term however there will be more possibilities with the Drupal 8 version, because it offers much richer APIs, allowing module developers to do even more.
At present the Drupal 8 integration only provides the default page logging functionality that stores the browsing journeys of your site’s visitors. It can however also be extended with a custom module to store other data. The Drupal 7 module has this page logging functionality and the Rules integration.
Link & Installation Instructions
The module is available on Drupal.org. For both versions, the PHP library dependencies are specified in a composer.json file. For D7, use Composer Manager, for D8, you can manage the composer dependencies globally. Consult the Drupal documentation on composer for more information.
Integration with the Rules module
Rules is a powerful Drupal module that enables site builders to define actions that will be executed when they get triggered by an event and when their conditions are met. With the help of Rules, it is possible to set up complex site behavior without having to write code. In other words, Rules turns clickers into developers. By building the Drupal connector module with a Rules integration, we’ve added a powerful content modelling tool to the Neo4J ecosystem that empowers non-coders to do complex things with graph databases.
For now the Rules integration in the Neo4J module requires you to execute a custom Cypher query as an action. In the future we could imagine creating a GUI that lets you compose the query so you could select the data sources and the way you want to store them in the database. This is something we could do if there is sufficient demand for it. At this point you can use data sources from Drupal by including the appropriate tokens as query parameters. You could for example use the {node__nid} token to refer to the currently active page context (more details in the example below). Using tokens, the Rules module allows you to hook into a wide range of processes that happen in Drupal, that can trigger almost any data available in the Drupal context to be stored in a graph database.
Try out the module
In our tutorial we’ve used the Drupal 7 module, since it has for now more interesting capabilities.
First, download the module into your local Drupal installation, and install the connector with composer. Download Neo4j, install, start it, open the web-interface on localhost:7474 and set the initial password. After you have enabled the Neo4j module, go to the configuration page, and enter the details for the connection.
After enabling the module, go to the Configuration page and click on Neo4j.
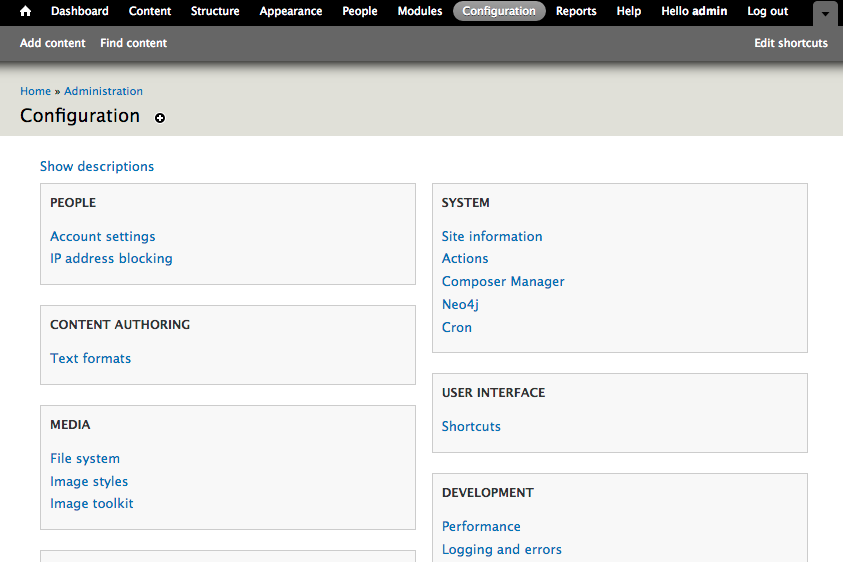
On the “General” tab, enter the credentials for your database. We recommend using the bolt protocol instead of http if it is available.
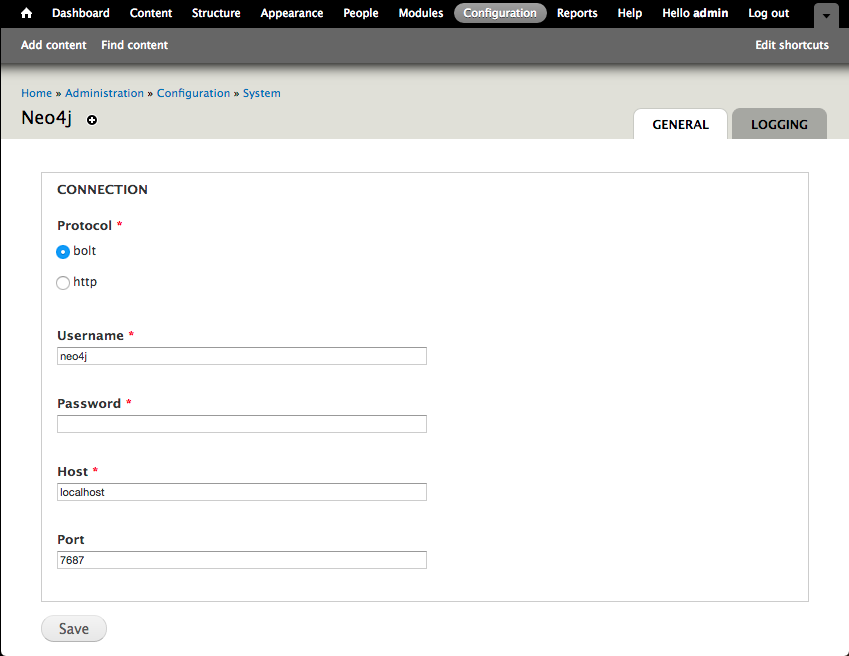
To enable page logging, check the “Page log” checkbox on the “Logging” tab and click on the “Save Configuration” button.
The page log feature will save 3 types of graph nodes: Page, User and Visit. The Page contains very basic information about the page itself. The User contains the user ID. These two are only recorded once. The Visit node contains data for the specific page visit, like the timestamp or the user’s IP address. The visit nodes are also connected for the same user, storing the user’s path on the site.
To set up the rules example, go to the rules admin page and create a new rule.
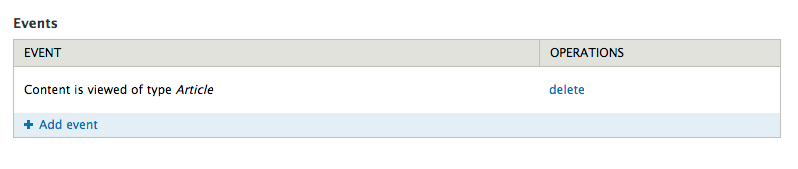
Add an event. For this example, use a content view of a content type.
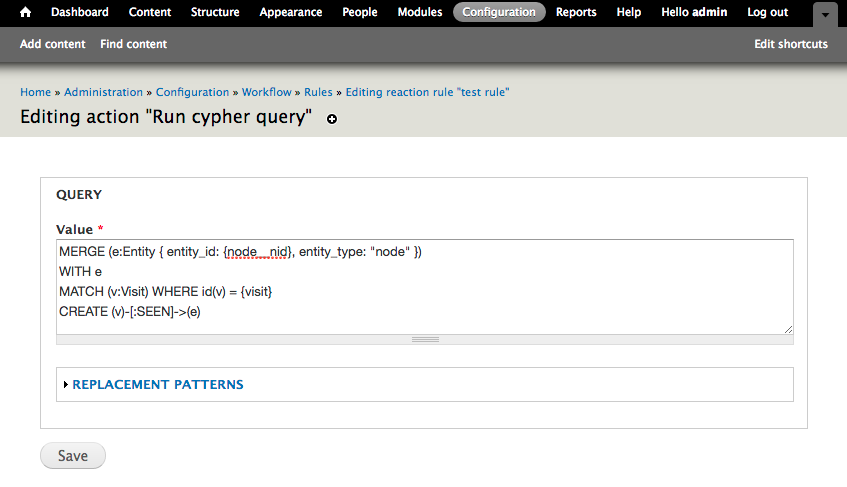
When you add an action, select “Run cypher query”, and in the settings, enter the following query:
MERGE (e:Entity { entity_id: {node__nid}, entity_type: "node" })
WITH e
MATCH (v:Visit) WHERE id(v) = {visit}
CREATE (v)-[:SEEN]->(e)
This query uses two parameters. The first one {node__nid} is generated from Drupal’s replacement tokens. The second one, {visit} is a special pattern that references the id of the Visit node in the graph database (not the Drupal node), so it is easy to connect future nodes in the graph database to the current visit. To get the full list of available parameters (like {node__title} or field values), open the “Replacement patterns” fieldset.
In this example, MERGE (get-or-create) ensures that there is a node in the graph database for the Drupal node that is being visited, and that a connection is created between that node and the current visit.
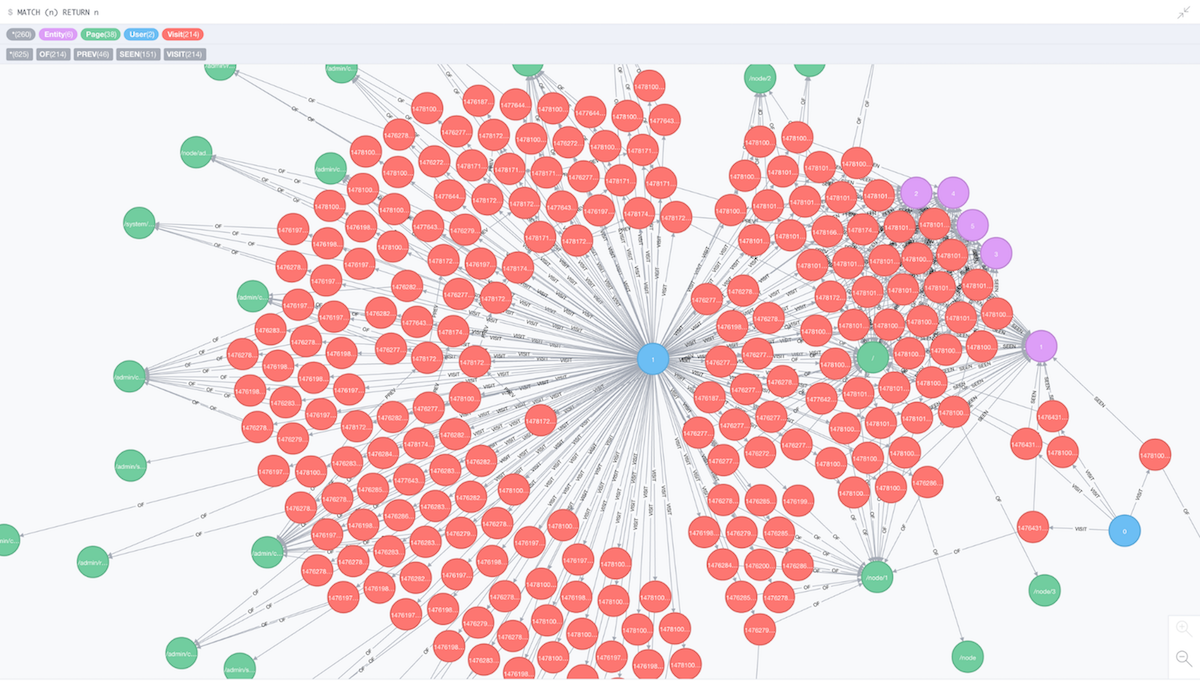
After visiting a site with this plugin enabled, the graph that is created will look something like this:
How to create an integration module
The following tutorial shows how to create a simple module for Drupal 7. The Drupal 8 version of the API module is very similar, the main difference is that the Neo4j client object is available through a service, not as a global function.
Our example module will recommend content based on user data.
Create a directory called neo4j_hello_world in sites/all/modules/custom, and a file called neo4j_hello_world.info.
name = Neo4j Hello World package = Neo4j core = 7.x dependencies[] = neo4j
In the module file, create the info hook for the block
/**
* Implements hook_block_info().
*/
function neo4j_hello_world_block_info() {
return [
'neo4j_recommendation' => [
'info' => t('Neo4j content recommendation'),
'cache' => DRUPAL_NO_CACHE,
],
];
}
Following that, implement the block view hook
/**
* Implements hook_block_view().
*/
function neo4j_hello_world_block_view($delta = '') {
$block = [];
switch ($delta) {
case 'neo4j_recommendation':
$block['subject'] = t('Recommended content');
$block['content'] = [];
if (($page_node = menu_get_object()) && !empty($page_node->nid)) {
$recommended_nodes =
_neo4j_hello_world_get_recommendations($page_node->nid);
$links = array_map(function ($node) {
return l($node->title, "node/{$node->nid}");
}, $recommended_nodes);
$block['content'] = [
'#theme' => 'item_list',
'#items' => $links,
];
}
break;
}
return $block;
}
This block only has content on node pages. The helper function _neo4j_hello_world_get_recommendations() returns the list of node objects, and the list gets transformed into links by array_map().
Finally implement the recommendation function that executes the Cypher query to get the recommended pages from the Neo4j database:
/**
* Retrieves a list of nodes that are usually visited by users who visit node/$nid.
*
* @param $nid
* Page node id.
* @return array
* List of recommended nodes.
*/
function _neo4j_hello_world_get_recommendations($nid) {
$client = neo4j_get_client();
if ($client) {
try {
$res = $client->run("
MATCH (p:Page)<-[:OF]-(:Visit)-[:SEEN]->(pe:Entity { entity_type: {entity_type}, entity_id: {entity_id} })
MATCH (p)<-[:OF]-(:Visit)-[prev:PREV*..10]-(:Visit)-[:SEEN]->(e:Entity)
WHERE NOT e = pe AND e.entity_type = {entity_type}
RETURN e.entity_id AS entity_id, avg(size(prev)) AS distance
ORDER BY distance ASC
LIMIT 10
", [
'entity_id' => $nid,
'entity_type' => 'node',
]);
$nids = [];
foreach ($res->records() as $record) {
$nids[] = $record->get('entity_id');
}
$nodes = node_load_multiple($nids);
$ordered_nodes = [];
foreach ($nids as $nid) {
$ordered_nodes[] = $nodes[$nid];
}
return $ordered_nodes;
} catch (Exception $e) {
watchdog_exception('neo4j hw', $e);
}
}
return [];
}
In this function, first we make sure that the client is available. Then make sure that when you interact with the client object, you wrap the code in a try-catch block.
The most interesting part of this function is the recommendation-query itself. Let’s have a look at the graph model again.
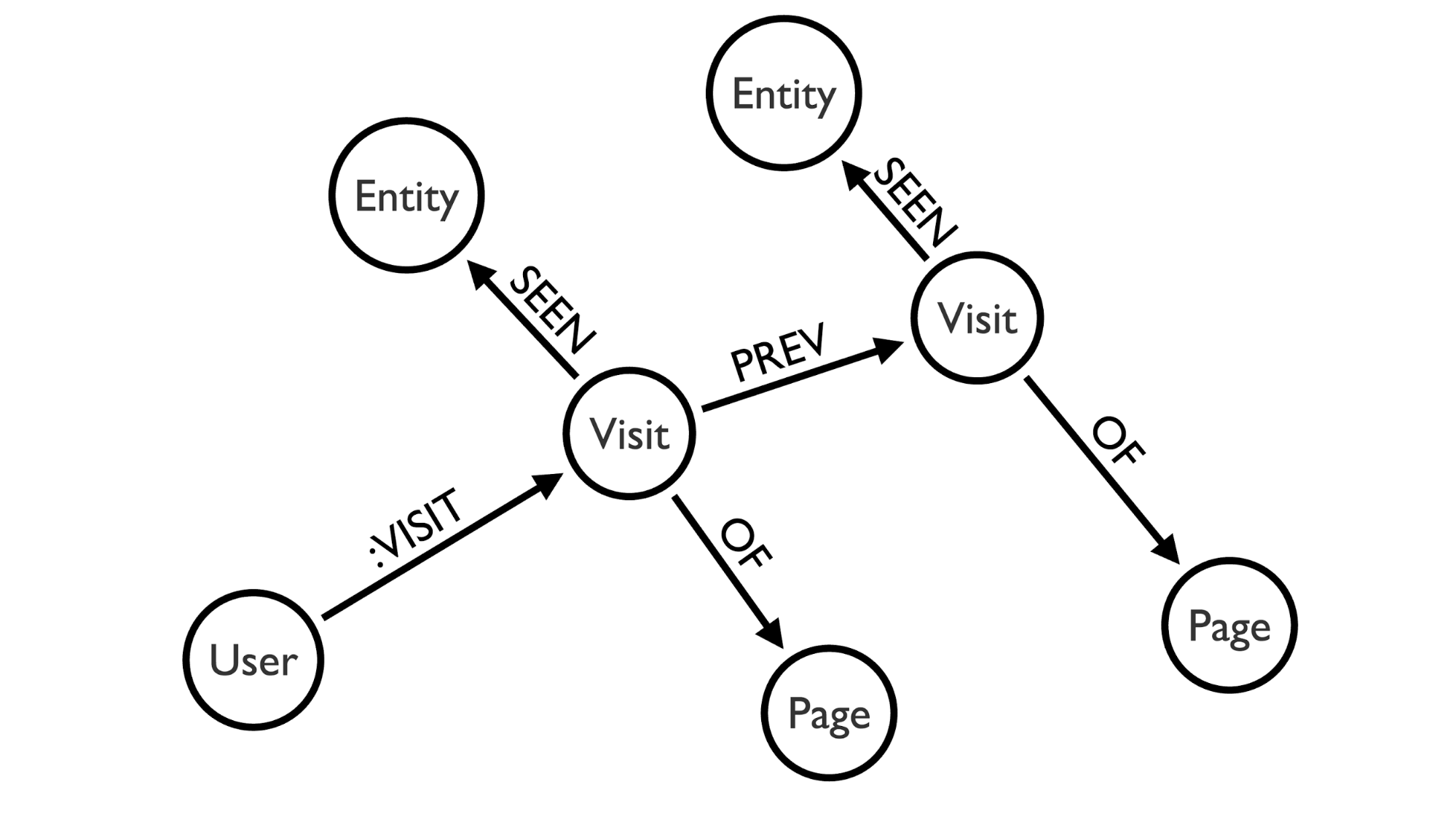
MATCH (p:Page)<-[:OF]-(:Visit)-[:SEEN]->(pe:Entity { entity_type: {entity_type}, entity_id: {entity_id} })
First it matches all pages for the Drupal node we’re currently visiting which we already have visit nodes in the database.
MATCH (p)<-[:OF]-(:Visit)-[prev:PREV*..10]-(:Visit)-[:SEEN]->(e:Entity)
The second match matches the entities (Drupal nodes) that can be connected to the pages from the previous match with a distance of maximum 10 page visits.
WHERE NOT e = pe AND e.entity_type = {entity_type}
The WHERE statement filters the results from the previous matches, excluding the current entity, and narrowing the results to nodes.
RETURN e.entity_id AS entity_id, avg(size(prev)) AS distance
In the RETURN statement, a simple weight is generated, from an average of the distance between the entities. This weight will be too simple for most real world applications, but to keep things simple, it is sufficient for the scope of this example.
ORDER BY distance ASC
LIMIT 10
Finally order by the distance and take the first 10 items.
In an example graph starting from Entity 1 on the left, all these Entities (2,3,4) on the right would be returned as recommendations:
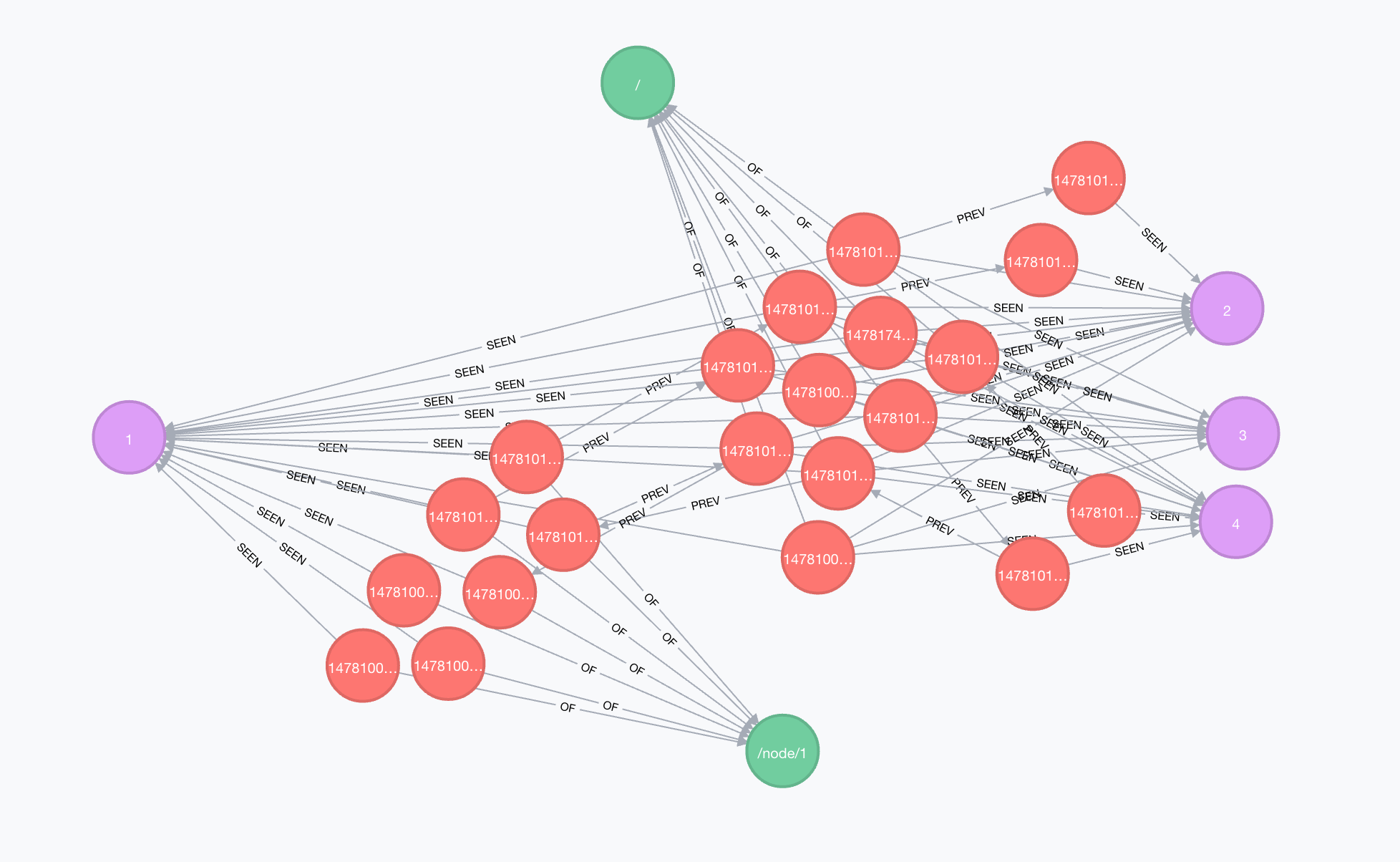
After the query, a foreach loop takes a list of node ids, and with a node_load_multiple() we load the nodes from the database that are then resorted.
Closing Thoughts
These were very basic examples of how the module can be used to start building a graph database. Please try it out and let us know how you would like to use the module, we would love to hear about any applications you think this could be used for. Also if you run into any errors you can report them in
Neo4j is already used in production on Drupal sites, but all those implementations were one-off integrations. We hope that this project could be the start of a community effort for a full featured Neo4j integration that enables even complex use cases without much coding.
We at Pronovix are a Drupal consultancy, if you need a deeper integration, or if you would like to extend the functionality of the module please let us know us. We are specialised in documentation systems and developer portals, systems that need to deliver content in the context of a user’s activities and problems.
That is why we started working with Neo4J because we want to use it to deliver personalised help content proactively. We would like to become the go-to company for organisations that need help with their Neo4j project on Drupal. That is why we invest in this module and actively share knowledge about interesting problems graph databases can solve in the CMS world. If you want to get notified when we publish a new blogpost, sign up for our Documentation Automation & Personalisation, AI, And Graph Databases mailinglist.
If you want to chat with us, you can find us on the #neo4j-drupal channel in the neo4j.com/slack. Our company’s site is at https://pronovix.com. You can also contact us through our contact form, or connect with Kristof on Linkedin.
Thanks to my colleague Tamás Demeter-Haludka for co-authoring.
